
はじめに
gitコマンドの動作の理解で困ることが続いたため、そもそもgitの仕組みってどうなってるの?というところを勉強してみました!
gitのデータ
- gitのデータはスナップショットで保存されています
- git graph とかで差分だけ表示されているのをみて、変更した分だけ保存しているのかな〜と勝手にイメージをしていました笑
- スナップショットで保存するメリット
- 操作の高速化
- ブランチをきったりマージする際に差分計算が不要になります
- 堅牢なデータ管理の実現
- コミット同士が疎結合になります
- 前のコミットが消えてしまっているからあるコミットが復元できない、ということが起きません
- 操作の高速化
gitオブジェクトの管理
- 概要
- ソースコードその他の管理対象はファイルごとに圧縮されて、ファイルの中身に固有のハッシュ値で管理されます
- ある時点でのスナップショット(=コミット)は、ディレクトリ構造を反映した木構造とハッシュ値で管理されます。
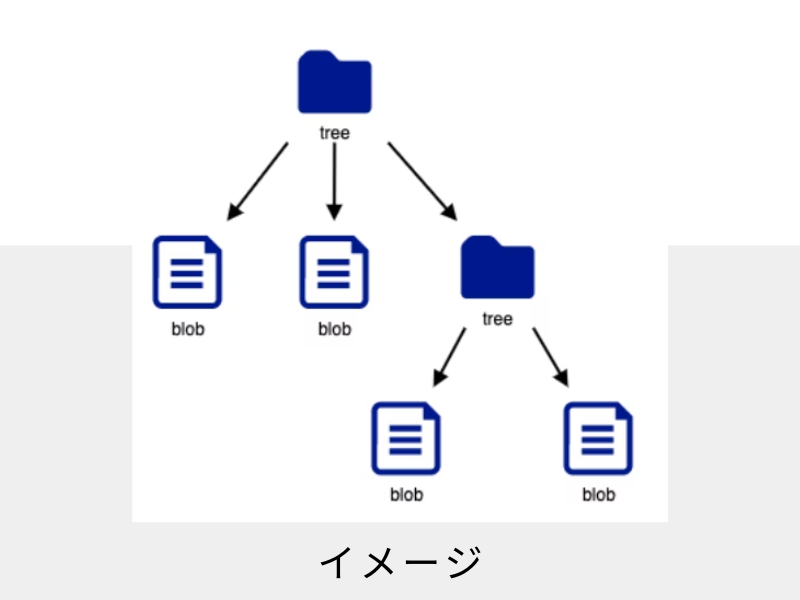
- オブジェクトの種類
- blobオブジェクト
- ファイルの中身そのものを圧縮したもの
- ファイルに対応している
- treeオブジェクト
- ファイル名とファイルの中身の組み合わせ(ファイル構造)を保存しているもの
- ディレクトリに対応している
- blobオブジェクト
https://qiita.com/marchin_1989/items/2ec01553e907f3a9e6bb イメージ図
- 保存場所
- 「.git/objects」フォルダ配下
- 実際にフォルダの中身を確認してみるとイメージが持ちやすいので、一度試してみることをおすすめします!
コミットまでの流れを確認
全体の流れ
- index.html を作成
- git add
- git commit
gitの構成
- ワークツリー
- ファイルを作成したりソースコードを書いたり、実際に作業を行う場所のこと
- ステージ(インデックス)
- コミットする準備をする場所のこと
- リポジトリ
- ローカルリポジトリ
- ローカルマシン上で、ファイルやディレクトリの状態を記録する場所
- リモートリポジトリ
- ネットワーク上で、ファイルやディレクトリの状態を記録する場所
- GitLabとかGithubとか
- 余談ですが、GitLabのキャラクターってたぬきなんですね✨
- ローカルリポジトリ
内容の確認
- index.html を作成
- git add
- index.html のファイルの中身を圧縮したファイルを作成し、ローカルリポジトリに保存
- このときのファイル名は、主にファイルの中身を元にハッシュ関数で暗号化した文字列になる
- ファイル名「index.html」と、内容にあたる「圧縮ファイル」をマッピングした情報をインデックスに追加
- index.html のファイルの中身を圧縮したファイルを作成し、ローカルリポジトリに保存
- git commit
- インデックスのファイル構成を元にツリーファイルを新規作成
- コミットファイルの作成
終わりに
gitコマンドを理解しようとしたときに、まず構成を理解しておくと、その構成の中の「どこで」「なにを」やっているか考えられるようになるのでいいなと思いました。
勉強方法のひとつとして参考になれば嬉しいです!


コメント